
|

|
|
 |
 |
 |
 |
Genomics:Genome Assembly
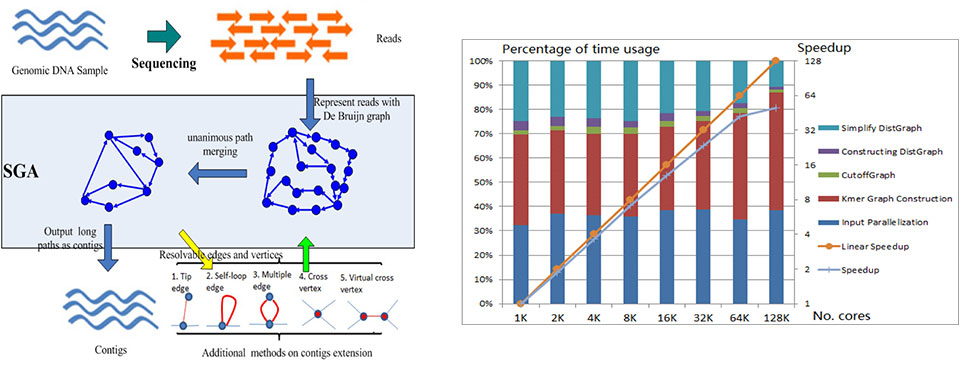
Next Generation Sequencing techniques generate vast amount of genetic data that requires highly scalable and efficient tools for analyzing these data. Sequencing reads from the machines can be in the range of TB-PB range, sequential algorithms can no longer meet the needs. In our lab, we focus on developing De Bruijn graph based approach for assembling the raw reads. Through mathematical abstraction and building an asynchronous computing model, we have developed SWAP-Assembler for large scale genome assembly. We have demonstrated that SWAP-Assembler can scale to tens of thousands cores on Mira@Argonne National Lab, and Tianhe-2@National Supercomputing Center in Guangzhou. When tested on MIRA, SWAP can scale up to 131,072 cores on 4 Tarabytes data from 1000 human genome dataset using several minutes. This is an open source project, and the software can be download from http://sourceforge.net/projects/swapassembler/.
Copyright © 2017 High Performance Computing Center, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences.
Designed by Chunxia Zeng. Dec 15 2017.